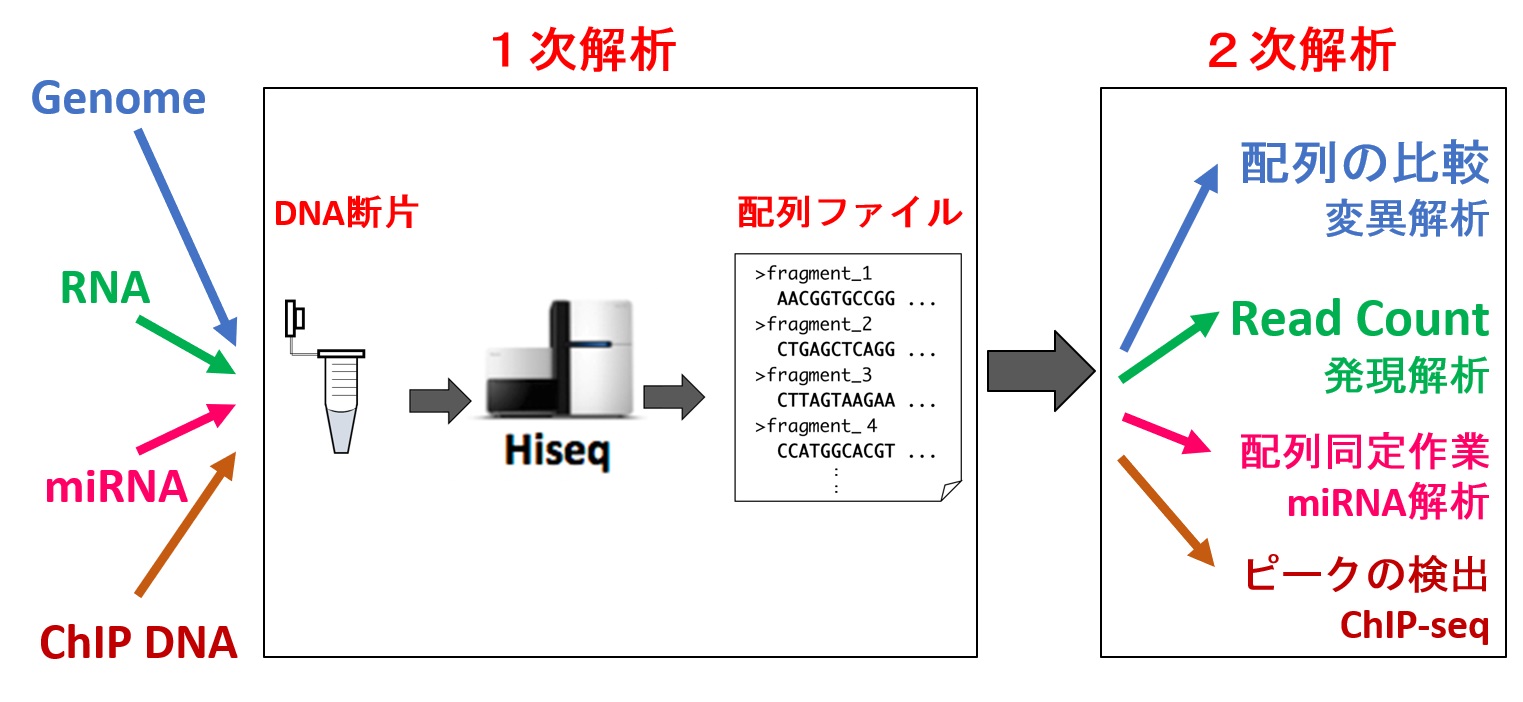
前回の「次世代シーケンサー(NGS)とは」の続きです。NGSの解析は大きく分けて二段階あります。それはウェットと呼ばれる試薬などを使った実験室での作業とドライと呼ばれるコンピューターの計算を使った作業です。前者はNGSを使用してDNA溶液から配列決定を行い、一次解析とよく言われます。後者はデータとなった大量の配列を処理し、二次解析とよく言われます。
- 一次解析
- 基本的にNGSは配列の決定のみを行います。DNAの断片が入った溶液からランダムに大量に配列を読み、データファイルが得られます。
- 二次解析
- 一次解析で得られるのは配列データのみである為、考察できるように計算を行います。非常に大量の配列が得られるため、コンピュータの計算にて実行します。
図のように、INPUTのサンプルと二次解析を変更することにより、手法の多様性があります。
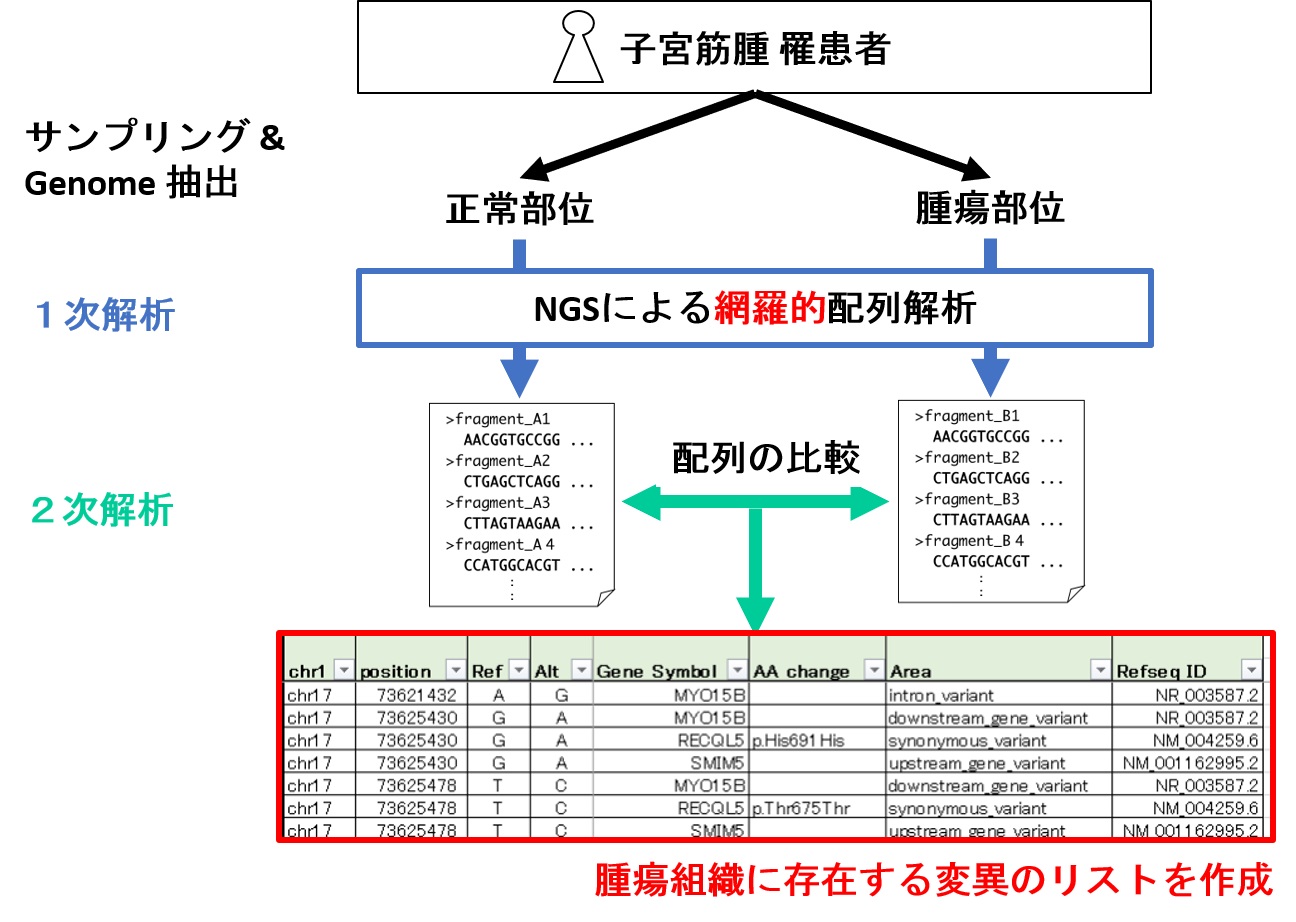
NGSを使用した研究例
“MED12, the Mediator Complex Subunit 12 Gene, Is Mutated at High Frequency in Uterine Leiomyomas” Netta Mäkinen et al.
正常とターゲットを比較することで、ターゲットに特異的な変異をリストアップしています。さらに、各人の特異的な変異を除くため、17人の患者で同様にリストアップを行い、17のリストから共通した変異を探しています。
次回はNGSを使う際の注意点についてお話します。→次回「NGSを活用する際の注意点」